LSTM与量化交易
2023-04-20 1.LSTM简介
LSTM(Long Short-Term Memory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM脱根于RNN,但相较于RNN(Recurrent Neural Network),LSTM能够解决解决长序列训练过程中的梯度消失和梯度爆炸问题,在处理时间序列数据上有着巨大的优势。
自2015年由Google提出后,LSTM在科技领域已经有了多个方面的应用。基于LSTM的系统广泛应用于翻译语言、控制机器人、图像分析、文档摘要、语音识别图像识别和股票预测等方面。
2.LSTM与RNN区别
2.1RNN的网络结构
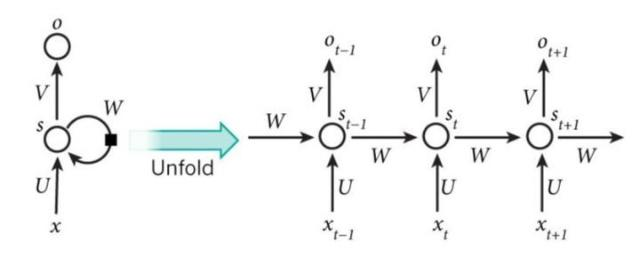
RNN的提出是为了解决具有时序关联性的问题,例如股票趋势预测,需要上一时刻的股票价格输入作为下一时刻的输出。为解决这个问题,RNN提出了一个独特的网络结构。
上图为RNN的一个简单的网络结构示例。其中x为输入层,s为隐藏层,o为输入层,U,V为各层之间的权重参数。右侧图像为左侧图像展开为平面时的图像。
从上图我们可以清晰的看出,RNN的输出不仅和上层的输出相关,还与过往所有层的输入有关。通过建立当前输出与过往所有输入的关系,RNN获取了处理时序问题的能力。
2.2LSTM的网络结构
从上述的介绍我们知道,RNN每层的输出是依赖于在其之前的每一轮的输入。但是随着时间的推移,很久之前的输入数据所占的权重是越来越小。在处理常规时序问题时,这样处理是科学的。因为时间越久远的数据一般而言对当前的影响越小。但是很多问题是存在长期依赖的问题。长期依赖是指当前系统的状态,可能受很长时间之前系统状态的影响。
为解决这个问题,LSTM提出来一个三门结构,即输入门,输出门和遗忘门。当一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。图示为一个典型的LSTM结构。其中红色边框中的为遗忘门,橙色边框中的为输入门,绿色边框中的为输出门。当信息输入遗忘门时,遗忘门会对上级的输入数据和当前输入进行判断,输出一个0到1之间的数,0表示完全舍弃,1表示完全保留。数据输入至输入门时有两个过程,一个是有输入门对数据进行处理决定什么值需要更新,另一个是由tanh函数对输入数据进行激活。将信息输出值输出门,由输出门决定输出那些信息,最后有tanh函数进行激活。
通过LSTM独特的三门结构,LSTM成功的解决RNN在长期依赖问题的问题,同时也大大的加快的运算效率。
3.量化交易
量化交易是指以先进的数学模型替代人为的主观判断,利用计算机技术从庞大的历史数据中海选能带来超额收益的多种"大概率"事件以制定策略。量化交易是一门由金融、数学、计算机等学科交叉融合而来的学科。其中金融学用于量化交易模型建立的理论指导,数学用于模型的建立和推导,计算机用于模型的实现。
一个完整的量化交易模型大致可以分为三个部分,数据输入,策略的研究和结果输出。
其中输入的数据可以包括当前的一个市场的行情、您的投资经验、公司的财务数据等等,策略部分包括选择哪些股票,在何时进行选股,何时止盈止损等,输出的结果可以包含买入卖出的信号,产生的交易费用和产生的利润等。
4.LSTM运用于量化交易
LSTM运用于量化交易主要用于股票和期权的价格。以下简要的介绍一下LSTM用于预测股票价格的流程。
整个流程大致可以分为4步,数据清理,模型搭建,分析调优和对模型的一个总结分析。
数据清理过程主要是对数据进行一个预处理,包括选择哪些股票,选择的时段,选择哪些交易数据,对数据的归一化等方式。模型的搭建主要是对神经网络的构建。一个基于LSTM的神经网络模型大致可以分为数据输入、LSTM层,FC层、输出层和数据输出层。
LSTM层即是上文所描述的LSTM结构。FC层是对LSTM输出的数据进行整理,并输出一个结果。输出层为最终结果的判断。通过对神经网络的不断改正和参数优化,以及对模型性能的分析总结,即完成了一次基于LSTM的股票价格预测系统的构建。
同时,LSTM还可以用于用户情绪的分析。通过抓取各平台用户的评论,然后采用LSTM进行情感分类,最终得到一个市场用户情绪的总体画像。
5.参考文献
【1】Hochreiter, Sepp. Technische Universität München, Fakultät für Informatik, Munich, Germany;Schmidhuber, Jürgen.Long short-term memory.[J].Neural computation,1997,Vol.9(8): 1735-1780。
【2】杨丽,吴雨茜,王俊丽,刘义理.循环神经网络研究综述[J].计算机应用,2018,第38卷(202): 1-6,26