人工智能与量化交易
2023-02-21 1.人工智能简介
人工智能(AI)是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。AI包含机器学习、深度学习、强化学习等研究方向。人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作。
随着计算机科学技术的快速发展,人工智能在各个领域的应用也越来越广泛,其与各个学科技术相结合,已成为 各领域人士关注的焦点。将人工智能应用于量化交易,通过搭建不同的神经网络模型,对期货历史数据进行挖掘,找到期货历史价格与未来价格的非线性关系,实现对未来价格的预测,已成为历史发展的必然趋势。
2.量化CTA
2.1CTA量化交易策略分类
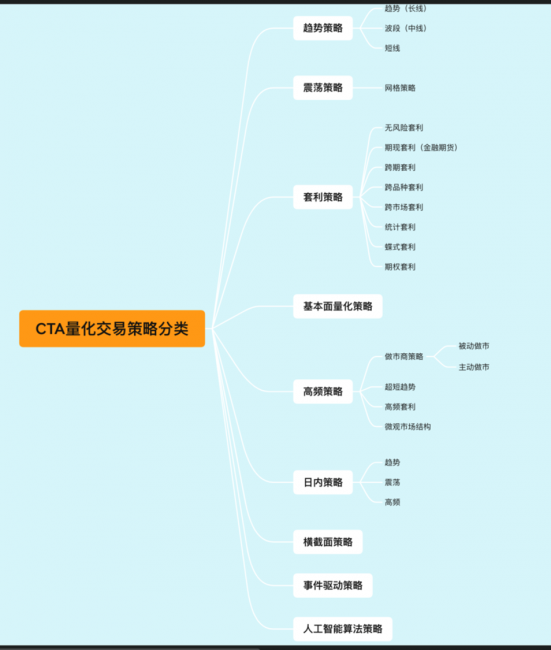
图1 CTA量化交易策略分类
CTA 量化交易策略可以大致分为这些方面:
1)趋势策略:分为长线趋势策略、中线波段策略以及短期趋势策略。
2)震荡策略:非趋势策略并不一定是反趋势策略,比方网格策略或者支撑压力位策略。
3)套利策略:套利策略包括无风险套利策略,期现套利策略,这里期现套利策略,主要指的是金融期货,像是股指,因为我们国内股票缺乏这种做空机制,股指会持续存在一定的贴水,所以会存在这种期现套利策略。
4)高频策略:高频策略分为做市商策略,做市场商策略又分为被动做市策略和主动做市策略,高频策略还包含了超短趋势策略,也就是以tick 数据为基础的这样一种短期趋势的高频交易和高频套利。
5)日内策略:日内策略进一步分成的日内的趋势策略、日内的震荡策略以及日内的高频策略。
6)另类策略:另外再有就是一些比较新的被称作为另类策略的一些新潮的交易策略,比方说像横截面策略,还有事件驱动策略,还有人工智能算法策略。人工智能算法策略的这个交易依据,就是上图中交易依据里面的计算科学,这方面的应用就是一个最新的应用。
2.2 量化因子
图2 量化因子
a.宏观因子:例如物价指数CPI、美国的核心PCE还有美元指数等等。
b.基本面因子:产量,表需,库存、开工率,还有新增产能等等,这些是工业品的整个产业链的基本面因子。农产品产业链的因子包括种植面积、种植进度、优良率、收获面积,还有收割进度,进口还有出口。这里面还有天气因素,这里也有一些数据是可以进行量化的,例如温度数据、降水量数据等。
c.统计因子:统计因子是一些统计特征方面的东西,比方说像偏度因子等。
d.技术因子:技术因子包括动量因子、波动率因子、均价突破因子,还有流动性因子等,进行技术分析方面所用的一些技术指标。
e.行为因子:行为因子与技术因子往往是一个互为表现的关系,技术因子体现的是一个市场行为的特征。行为因子包含了人们的恐惧心理,像恐慌指数,那么往往会通过动量或者波动率等这些技术因子体现出来。所以说技术因子是行为因子的一个表现形式。
f.事件因子:事件因子不是特别容易进行量化,如非农就业、美国农业部报告这种定期的事件。这种报告的公布,可以认为它是一种事件,对市场产生一种影响的事件,可以作为一种因子。
g.衍生品因子:那么对于一些品种来讲,它具有一些衍生物,例如原油期权,铜或者棉花都有期权。那么期权对于标的本身来讲可能会有一定的影响或者说一种指示作用,包括以后可能会推出的商品指数。
h.商品因子:这个跟商品期货本身有关系的,如Curve 因子,也就是期限结构曲线因子,债券的收益率曲线。期限结构因子,back 结构或contango结构,价值因子以及基差,期货升贴水情况,持仓因子等。
3.深度学习与量化交易
传统的投资策略倾向于定性分析,而让电脑代替人工进行 分析,就可以在整个市场中寻找投资标的物,投资的理念需要转 化成具体指标和参数,并按照程序去运行,能实时跟踪市场的变化情况,利用计算机提供的强大数据处理能力处理投资指标,在控制风险的情况下使收益达到最大化。随着人工智能技术的发 展,计算机可以大规模处理堆积如山的历史数据,与人工相比,不仅速度更快,准确率也更高,这使得投资以远超传统方式的规模发展起来。
人工智能是现在火热的研究的方向之一,任何一个东西如果想要变得更加智能,都会涉及人工智能算法。基于人工智能的量化CTA不仅能模拟人类思考问题的方式,还能够避免人类情绪化决策的问题,而且它能够自动地去发现市场里面的特殊现象。其中深度学习是人工智能领域中十分重要的研究方向,其具有非常强大的数据处理能力,金融交易领域存在着大量的历史数据,这些数据资源为量化交易提供了很好的数据基础。那么对于这样一种利用人工智能的方式进行的量化交易,大概分为这么四个部分:
第一步叫做预处理,也就是数据准备的工作。第二步将数据交给机器来进行学习。第三步就是学习完后,利用验证集数据进行验证,类似于回测。第四步是进行实盘交易,对这个新的产生的数据或未知的数据进行预测。
图3 量化交易步骤
4.ChatGPT与量化交易
最近基于人工智能的ChatGPT爆火,在量化投资中, ChatGPT可以完成一些简单的量化策略,例如构建平均回归模型,输出均线策略。理论上甚至可以利用Scikit-learn数据库(是针对Python编程语言的免费软件机器学习库)建立制作未来利率的预测模型,并利用MSE (均方误差)对其进行评价。智能投顾是以人工智能为基础的一项专业的投资咨询服务,ChatGPT这类AI机器人应用以后,能排除人的主观因素,提供更加客观的建议,还可以随着市场和环境的变化而不断演变创新。
参考文献:
[1] 刘力军,梁国鹏.基于人工智能的量化交易系统设计与实现[J].现代信息科技,2022,6(04):45-47.DOI:10.19850/j.cnki.2096-4706.2022.04.012.
[2] 赵雪. 深度学习在量化交易中的应用[D].北方工业大学,2019.
[3] 周爽,刘赟.金融行业中人工智能的应用前景[J].商场现代化,2020,No.920(11):133-135.DOI:10.14013/j.cnki.scxdh.2020.11.051.
[4] 于龙飞. 基于深度学习的股市量化交易系统设计与实现[D].山东大学,2020.DOI:10.27272/d.cnki.gshdu.2020.001064.
[5] 刘佳. CTA量化投资的组合资产配置研究[D].北京交通大学,2020.DOI:10.26944/d.cnki.gbfju.2020.002020.